




 C-Radar, le modèle prédictif des entreprises françaises par Data Publica
C-Radar, le modèle prédictif des entreprises françaises par Data Publica Comment s'assurer que votre marque n'est pas usurpé sur le Web ?
Comment s'assurer que votre marque n'est pas usurpé sur le Web ? Where Does My Tweet Go calcule le score de propagation de vos tweets
Where Does My Tweet Go calcule le score de propagation de vos tweets Retour sur 5 conférences d'AgoraCMS consacrées à la gestion de contenu Web
Retour sur 5 conférences d'AgoraCMS consacrées à la gestion de contenu WebL'outil Books Ngram Viewer de Google au service du text mining
Publié par Guillaume Main dans le dossier Outil | 27 avril 2011

Books Ngram Viewer est un nouvel outil accessible depuis le Labs de Google et qui s'appuie sur la base de données de Google Books. À peine mis en ligne en décembre 2010, le service brille déjà par sa redoutable efficacité et affiche ostensiblement ses ambitions : mettre un corpus linguistique, le plus large possible, à la disposition de tous les internautes. Pour autant, Books Ngram Viewer n'est pas exempte de tout reproche, ce qui laisse présager d'intéressantes améliorations dans les mois ou années à venir.
Le moins qu'on puisse dire, c'est que fort d'une solide expérience dans la numérisation de livres, Google peut aujourd'hui se targuer d'avoir scanné plus de 15 millions d'ouvrages, soit plus de 10% de tous les livres jamais édités dans le monde entier. Or, désormais, environ un tiers d'entre eux sont exploités dans le cadre du programme Books Ngram Viewer, un formidable outil permettant d'observer des tendances dans ce corpus linguistique rassemblant plus de 500 milliards de mots, dont 361 milliards en anglais (72%) et 45 milliards en français (9%).
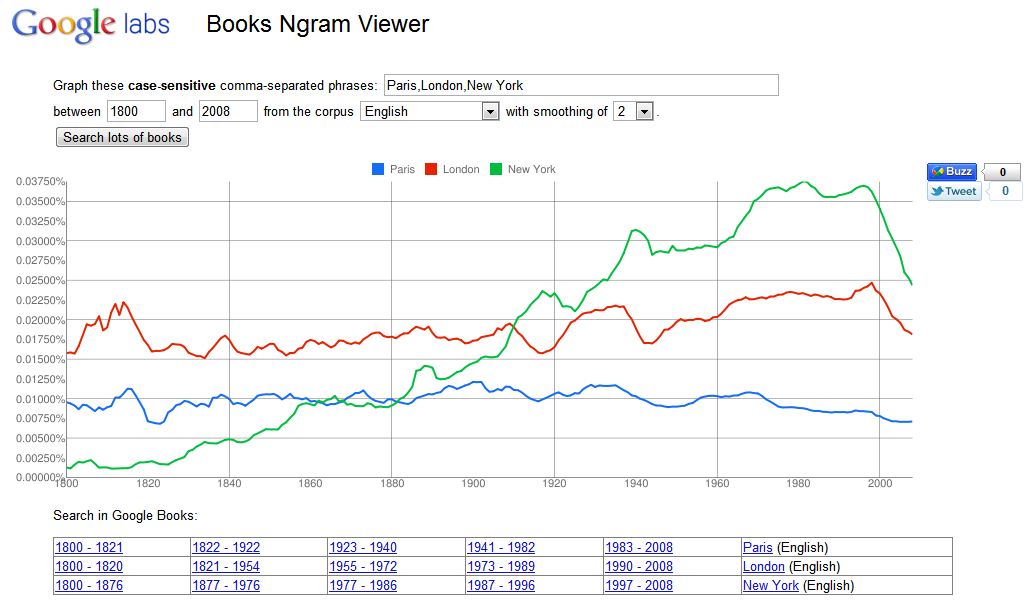
Paris, Londres, New York : les trois capitales du Monde ?
Pour illustrer l'ensemble, l'outil est capable de générer des graphiques à la volée, sous forme de courbes, comparables entre elles, et reflétant la notoriété d'une série d'expressions. L'algorithme est en effet particulièrement rapide et efficace puisque Books Ngram Viewer est capable d'analyser en quelques secondes toute la littérature remontant au moins jusqu'au 18ème siècle, et dans plusieurs langues : chinois, hébreu, français, allemand, russe, espagnol et trois versions d’anglais. Par ailleurs, les données du corpus sont pour le moment arrêtées à Juillet 2009.
Naturellement, Google n'oublie jamais que son objectif est avant tout de proposer un moteur de recherche à la fois infaillible et incontournable : ainsi, une sélection de livres contenant les expressions recherchées est accessible depuis la section Google Books.
Plusieurs considérations techniques permettent d'évaluer l'ampleur du projet :
- ont été retenus exclusivement les n-grams apparaissant au moins à 40 reprises dans l'ensemble du corpus
- le service intègre une option de lissage des courbes (le smoothing), facilitant l'observation des tendances et correspondant à la moyenne des résultats observés sur une durée à définir
- l'outil est capable de mesurer et comparer des expressions contenant jusqu'à 5 mots (on parle alors de "5-grams")
- il est possible de télécharger la totalité du corpus de chaque langue
- le corpus des 5-grams en langue française représente 800 fichiers de 14 Mo, soit plus de 11 To
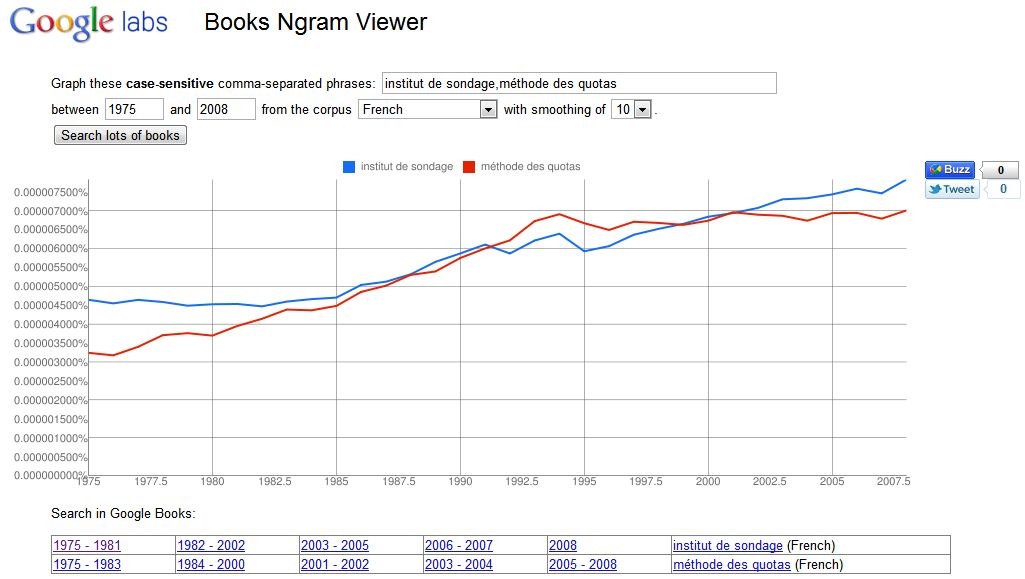
L'expression "institut de sondage" est-elle corrélée à l'expression "méthode des quotas" ?
Bien qu'il s'agisse d'un outil d'une richesse incomparable, il convient de signaler une série d'inconvénients relative à la conception de l'outil :
- les résultats manquent cruellement de contextualisation : les données sont brutes, les expressions sont ôtées de leur contexte
- les données statistiques sont extrêmement minimalistes : leur utilisation à posteriori n'est pas évidente
- signalons encore les nombreuses erreurs du système de reconnaissance de caractère, mais Google devrait savoir tirer un avantage de cet inconvénient en lançant un autre programme visant cette fois à améliorer les techniques d'OCR dans le cadre de la numérisation massive d'ouvrages
L'auteur du blog Déjà Vu regrette d'ailleurs que Books Ngram Viewer ne soit qu'un outil brut et difficile à utiliser si on ne dispose pas d'une culture générale suffisante. À cet égard, je vous recommande d'ailleurs son article, illustré d'une multitude d'exemples très parlant et trahissant notamment l'avènement des différentes réformes de l'orthographe. On ne peut en tout cas s'empêcher de penser qu'il s'agit d'un formidable outil au service du text mining.
Quoiqu'il en soit, je reste épaté devant l'efficacité (même relative) de cet outil : à l'instar d'un Google Insights for Search pour le Web, Google se surpasse une fois de plus et nous propose un passionnant outil, hautement chronophage, et permettant la mesure des tendances observables dans Google Books. Par ailleurs, je sais que les consultants en référencement naturel sont intéressés par l'outil : après tout, le Web 3.0 sera sémantique, ou ne sera pas.














Commentaires
Bonjour Guillaume! Merci de cet info! très intéressant!
Bonjour Generique ! Merci pour ce commentaire très intéressant ! Mais faut quand même pas me prendre pour un bleu ! :-)
T'iras vendre ton viagra ailleurs, j'enlève ton lien en signature.
pas de problemes ;) Bonne chance à toi !!!