




 Moins de 5% des entreprises respectent les critères importants pour leur site
Moins de 5% des entreprises respectent les critères importants pour leur site TextMaster compte les fautes d'orthographe dans ses emails et en fait une étude
TextMaster compte les fautes d'orthographe dans ses emails et en fait une étude 5 exemples de l'impact d'une émission de télévision sur le trafic Web
5 exemples de l'impact d'une émission de télévision sur le trafic Web ElectionScope : que penser du modèle prédictif qui voit Sarkozy l'emporter ?
ElectionScope : que penser du modèle prédictif qui voit Sarkozy l'emporter ?[INFOGRAPHIE] Un algorithme prédit le gagnant de la Coupe du Monde
Publié par Guillaume Main dans le dossier Analyse | 31 mai 2010

« Il existe de nombreuses façons de prédire les résultats de la Coupe du Monde - la plus simple étant d'utiliser le classement de la FIFA, à la manière de ces jeux très simples que sont les Top Trumps. Mais dans leur livre Why England Lose (HarperSport), Simon Kuper et Stefan Szymanski développent un modèle permettant de prédire les résultats du Football international et reposant essentiellement sur des données économiques. Ici, ils l'utilisent pour prédire la Coupe du Monde 2010.
Ils constatent qu'ils sont capables de prédire correctement l'issu de trois matchs sur quatre en utilisant une formule basée sur le rapport entre les populations des deux pays (les nations plus peuplées ont un plus grand vivier de joueurs talentueux), le PIB par habitant (plus il est élevé, plus ses ressources sont bonnes), l'expérience (plus vous jouez, plus vous vous améliorez) et un coefficient constant correspondant à l'avantage de jouer à domicile pour la nation organisatrice. Un PIB par habitant deux fois plus important ou une population deux fois plus nombreuse correspondent à un avantage de l'ordre d'un dixième de but. Cela ne semble pas beaucoup, mais ne perdez pas de vue que le PIB par habitant de la Suisse est cent fois plus élevé que celui du Ghana. D'un autre côté, avoir deux fois plus d'expérience équivaut à plus de la moitié d'un but, et le fait de jouer à domicile représente un avantage de pratiquement deux tiers de but. La méthode devine correctement le vainqueur 72% du temps (et a été pondéré afin de prendre en compte les équipes ayant fait mieux ou pire que prévu par le passé).
L'algorithme utilise les régressions linéaires et a été ajusté en fonction des résultats internationaux sur une période allant de 1980 à 2001 (les données s'appuient sur les archives du Football de l'Université de Londres). Le résultat obtenu correspond à la différence de but attendue; la victoire est attribuée à l'équipe ayant un score positif. Toutefois, si le résultat est inférieur à 0.1 dans la phase d'élimination directe, les développeurs examinent l'historique des performances relevées lors des tirs au but afin de les départager. Cet été, ils prévoient que l'Angleterre perde contre l'Allemagne (0.02) dès le début de la compétition. Les plus optimistes, qui ne tiennent pas compte de ces prédictions, parient sur une finale Angleterre - Brésil dont la cote est de 14 contre 1. »
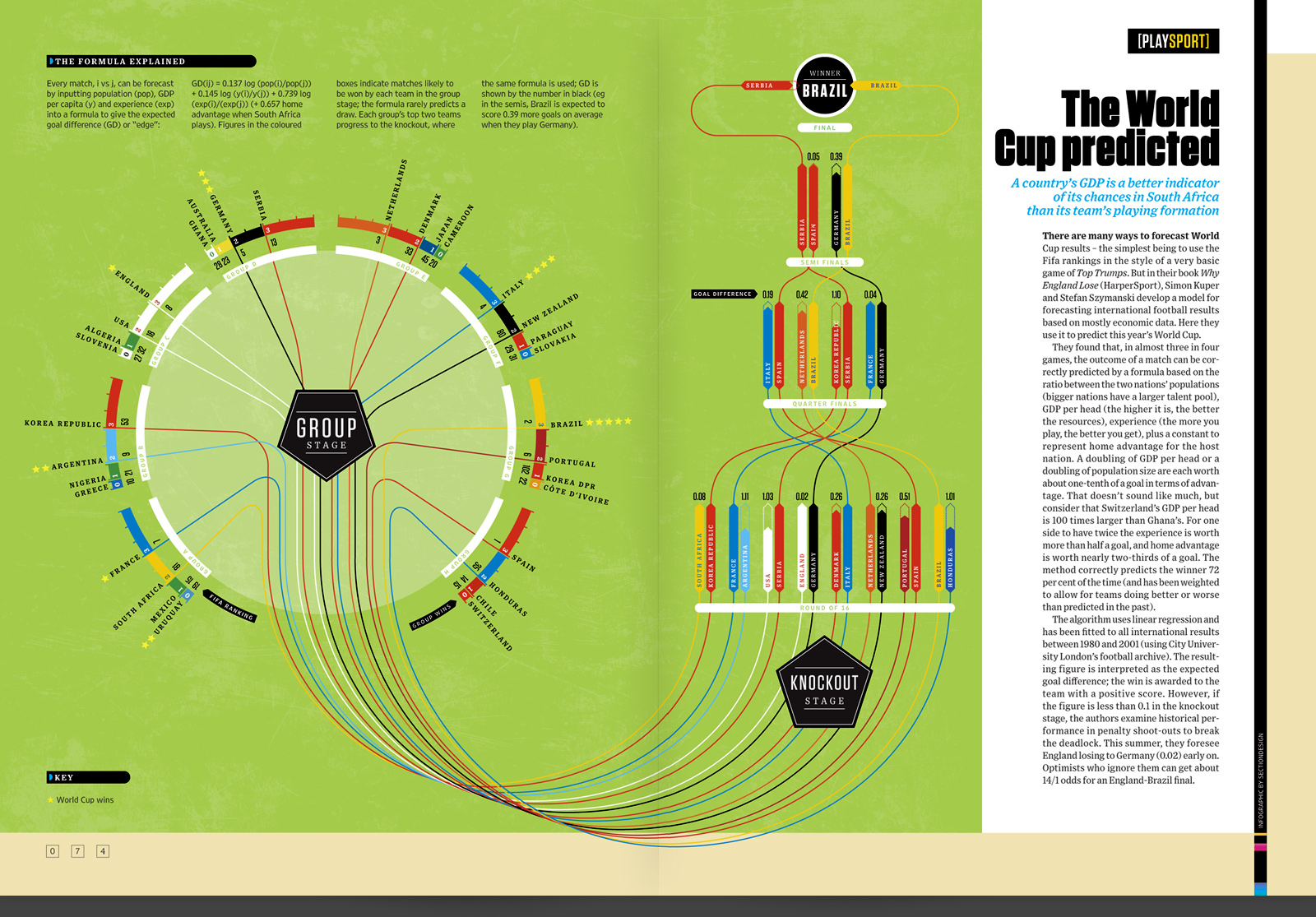
« Le résultat de chaque match, i vs j, est calculé en utilisant une formule contenant les variables "population" (pop), "PIB par habitant" (y) et "expérience" (exp) permettant d'obtenir la différence de but (DB) attendue : DB(ij) = 0.137 log(pop(i)/pop(j)) + 0.145 log(y(i)/y(j) + 0.739 log(exp(i)/exp(j)) (+0.657 pour l'avantage qu'a l'Afrique du Sud de jouer à domicile). Les nombres dans les cases en couleur indiquent les matchs susceptibles d'être gagnés par chaque équipe dans la phase de groupes; la formule prévoit rarement un match nul. Les deux meilleures équipes de chaque groupe progressent vers la phase à élimination directe dans laquelle la formule utilisée est la même, la DB est indiquée par les nombres dans les cases noires (par exemple, en demi-finale, l'algorithme prévoit que le Brésil marque 0.39 but de plus en moyenne contre l'Allemagne). »
Source : Wired UK, juin 2010
Traduction de l'anglais : Statosphere.fr
Selon cette modélisation statistique, la France s'inclinerait face à l'Allemagne en quart de finale et le Brésil remporterait la Coupe du Monde 2010.














Commentaires
personnellement je ne pense pas que l' on puisse prédire le vainqueur d' une coupe du monde sur des données économiques . ces messieurs , sans doute très intelligents , aurait constaté en regardant les matchs que l' Espagne est au-dessus des autres sélections et que la France ne devrait pas sortir de son groupe !!! merci pour la traduction
S'il suffisait de "regarder les matchs" pour prédire le gagnant de la Coupe du Monde 2010, alors il ne serait même plus nécessaire de la jouer. En ce qui concerne l'Espagne, ils l'envoient quand même jusqu'en demi-finale ce qui reste assez cohérent avec l'idée que les espagnols partent parmi les favoris. Par ailleurs, ton pronostic sur la France est tout à fait personnel. On disait déjà de la France qu'elle ne sortirait pas de son groupe en 2006 et elle est allée en finale.
Plus sérieusement, par rapport à l'étude, je trouve tout de même fascinant qu'une modélisation statistique puisse parvenir à "deviner" le gagnant d'un match de football trois fois sur quatre ! Et d'ailleurs, je trouve l'utilisation des données économiques très pertinentes. Car compte-tenu de la pléthore de footballeurs africains talentueux, comment expliquer autrement qu'ils ne se soient jamais imposés dans une Coupe du Monde ?
Il s'est un peu planté l'algorithme sur l'équipe de France.
Le facteur humain certainement ;)
Probablement... D'un autre côté, on peut se demander comment un pays comme la France peut avoir une équipe d'aussi bas niveau et, qui plus est, tout de même 7ème au classement FIFA !